PromptPG
Dynamic Prompt Learning via Policy Gradient for
Semi-structured Mathematical Reasoning
(ICLR 2023)
Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process.
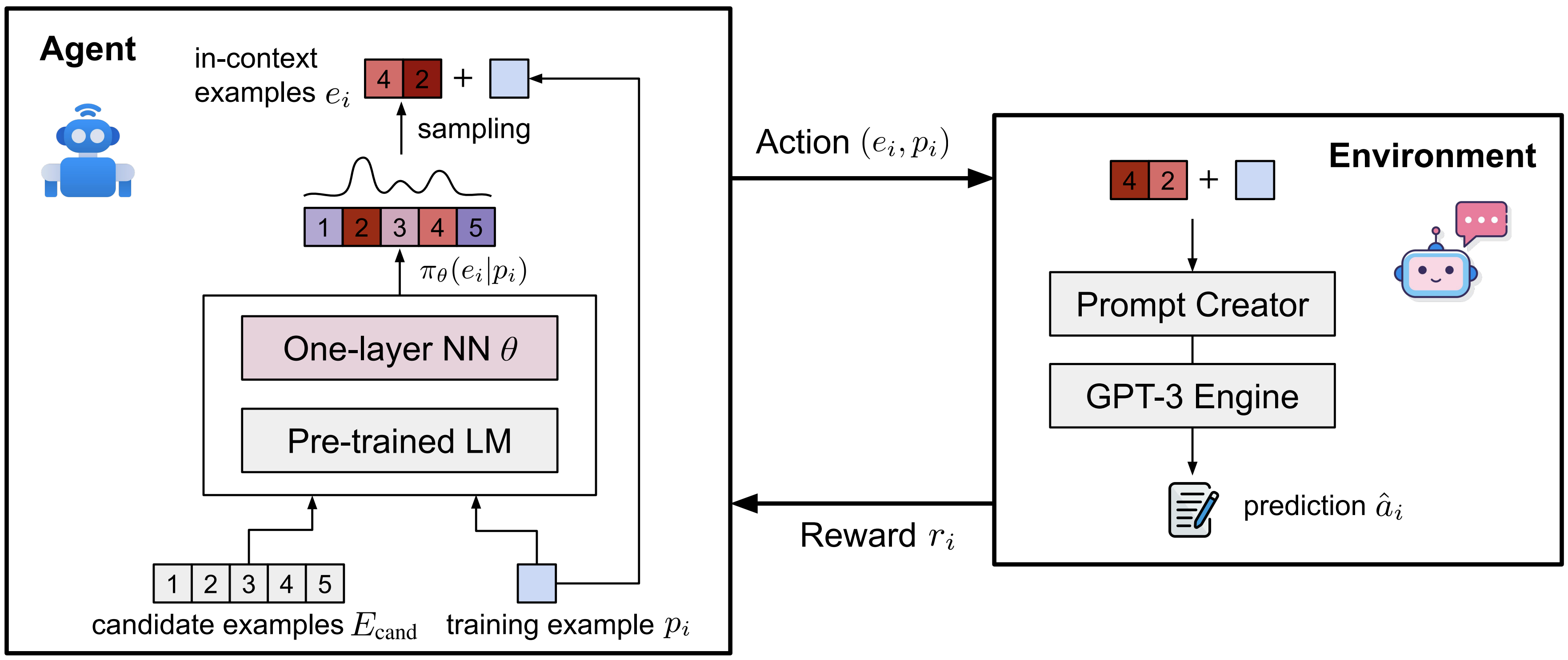
We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.
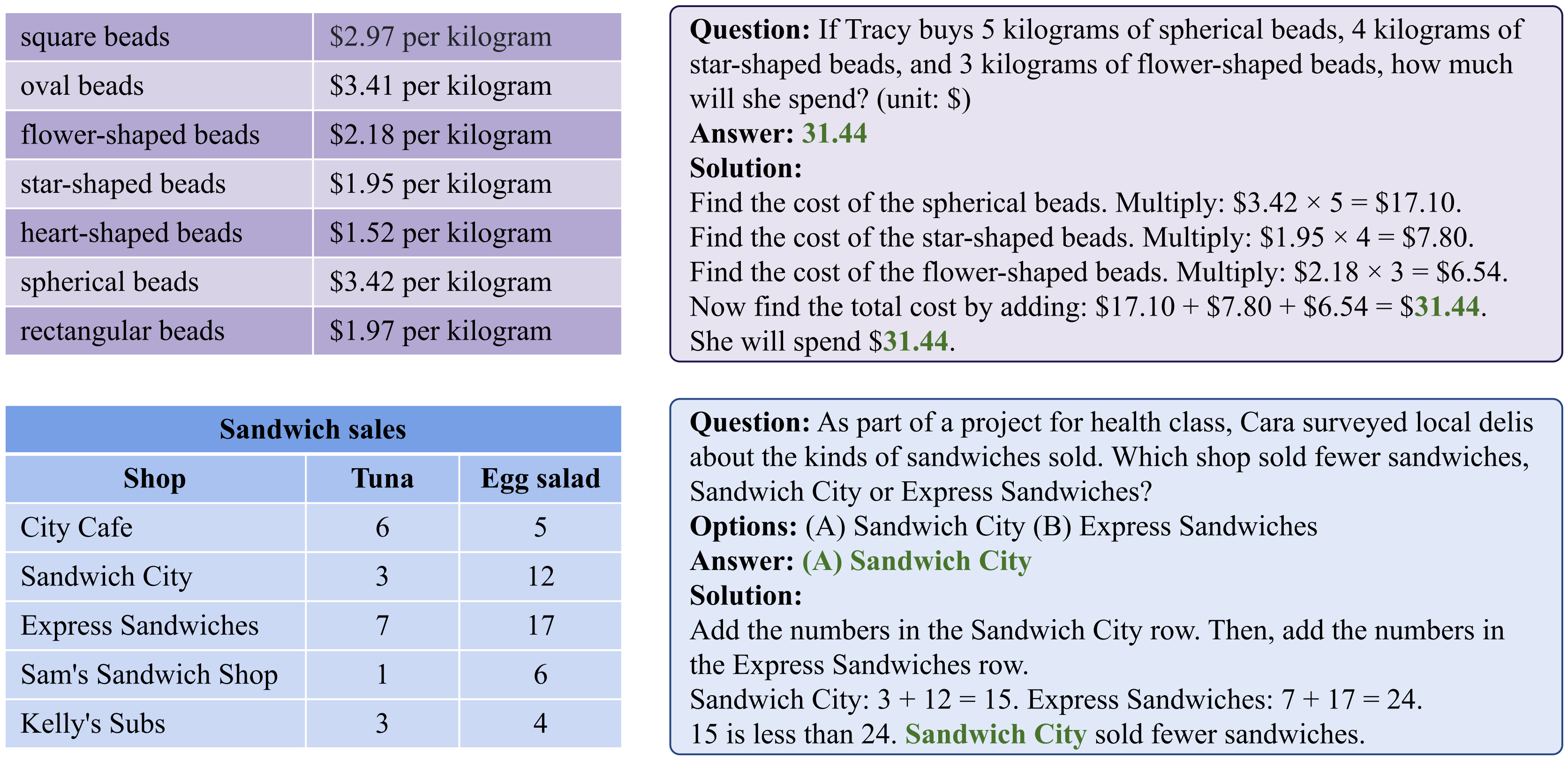
Below are two examples from the TabMWP dataset. One example is a free-text problem with a numerical answer and the other one is a multi-choice problem with a textual answer.
The TabMWP dataset contains 38,431 tabular math word problems. 74.7% of the questions in TabMWP belong to free-text questions, while 25.3% are multi-choice questions. There are 28,876 different questions, 6,153 different answers, and 35,442 different solutions, indicating that TabMWP has a rich diversity in the problem distribution. The questions have an average of 22.1 words in length and solutions of 49.5, showing that they have lexical richness. One distinct characteristic of TabMWP is that each problem is accompanied by a tabular context, without which the problem would be unsolvable. There are 37,644 different tables in total. The table has an average of 5.9 rows and 2.2 columns, which results in an average of 12.9 cells and a maximum of 54 cells. These statistics suggest that tables in TabMWP distribute diversely across semantics and layouts.
For more details, you can explore the datatset and check out the Explore page and Visualize page!
Our dataset is distributed under the CC BY-NC-SA (Attribution-NonCommercial-ShareAlike) license. You can download our dataset from Google Drive, or check out our github repository.
Given a tabular context and question text, the task is to generate an answer. The large pre-trained language model GPT-3 model exhibits strong performance on solving math word problems with the demonstrations of a few in-context examples. However, recent studies have shown that this type of few-shot learning can be highly unstable across different selections of in-context examples. It could be worse on TabMWP since its problems are distributed across multiple question types and diverse table layouts.
To alleviate this challenge, we further propose a novel approach that can learn to select in-context examples from a small amount of training data via policy Gradient for prompt learning, termed PromptPG. An agent learns to find optimal in-context examples from a candidate pool, with the goal of maximizing the prediction rewards on given training examples when interacting with the GPT-3 environment.

Below shows the correct prediction from the few-shot GPT-3 model with PromptPG for a free-text question example. This example requires looking up three items and their corresponding prices in the table, calculating their costs, and finally summing them up to get the final answer.
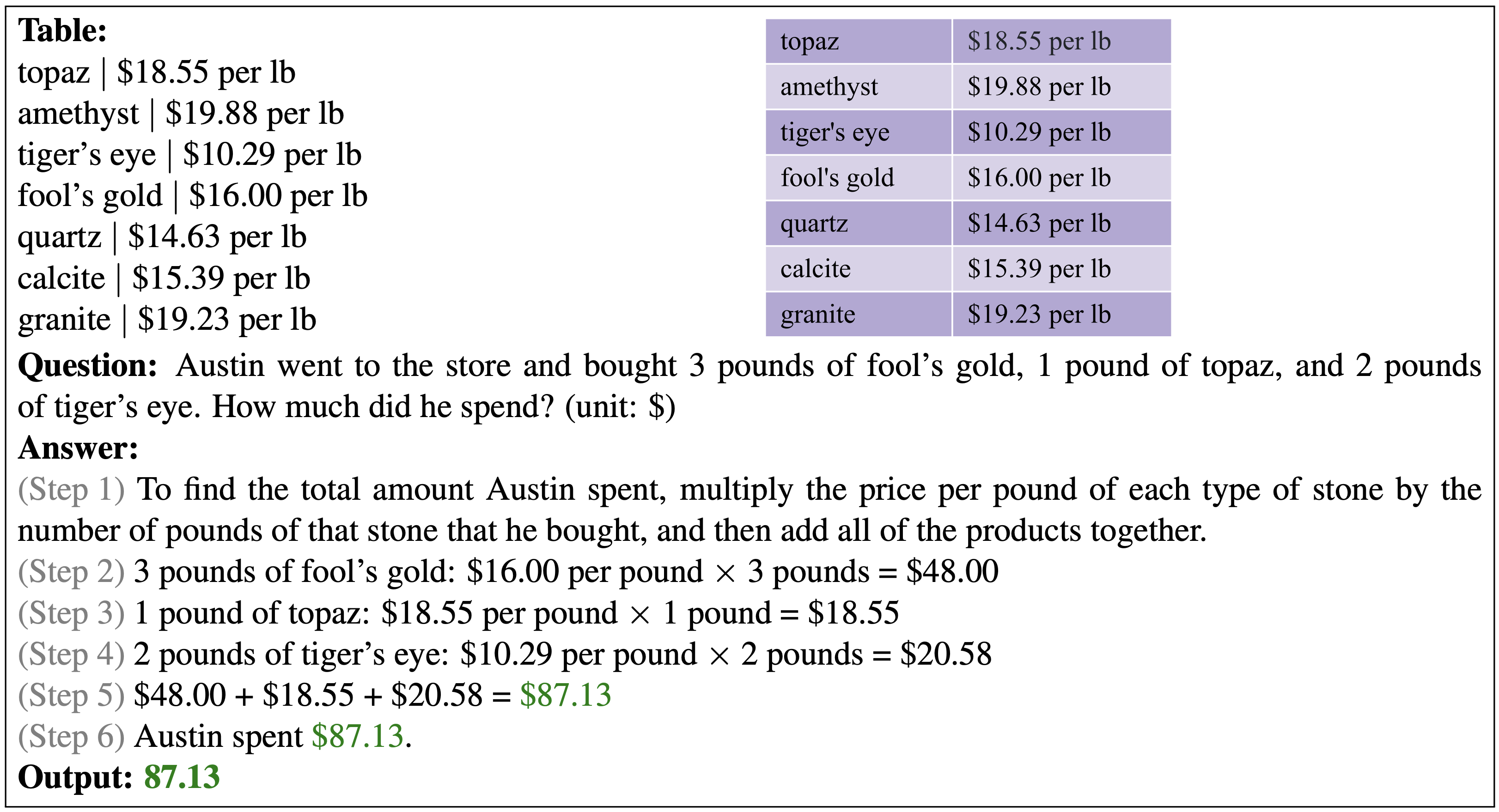
For more examples of the successful and failuare cases, you check out the Visualize page. The results of other baselines and recent work are reported at the Leaderboard page.
Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, Ashwin
Kalyan
ICLR 2023
Paper /
PDF
/
Code

View on the github repository.
If the paper, codes, or the dataset inspire you, please cite us:
@inproceedings{lu2023dynamic,
title={Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning},
author={Lu, Pan and Qiu, Liang and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Rajpurohit, Tanmay and Clark, Peter and Kalyan, Ashwin},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
1University of California, Los Angeles 2Georgia Institute of Technology 3Allen Institute for AI
Questions about our work, or want to get in touch? Contact Pan Lu at the contact page, or open up an issue on Github.

|

|

|







