There are two diffrent question types and five different answer types in the TabMWP dataset.

Each problem in TabMWP is accompanied by a tabular context, which is represented in three formats: an image, a semi-structured text, and a structured table.

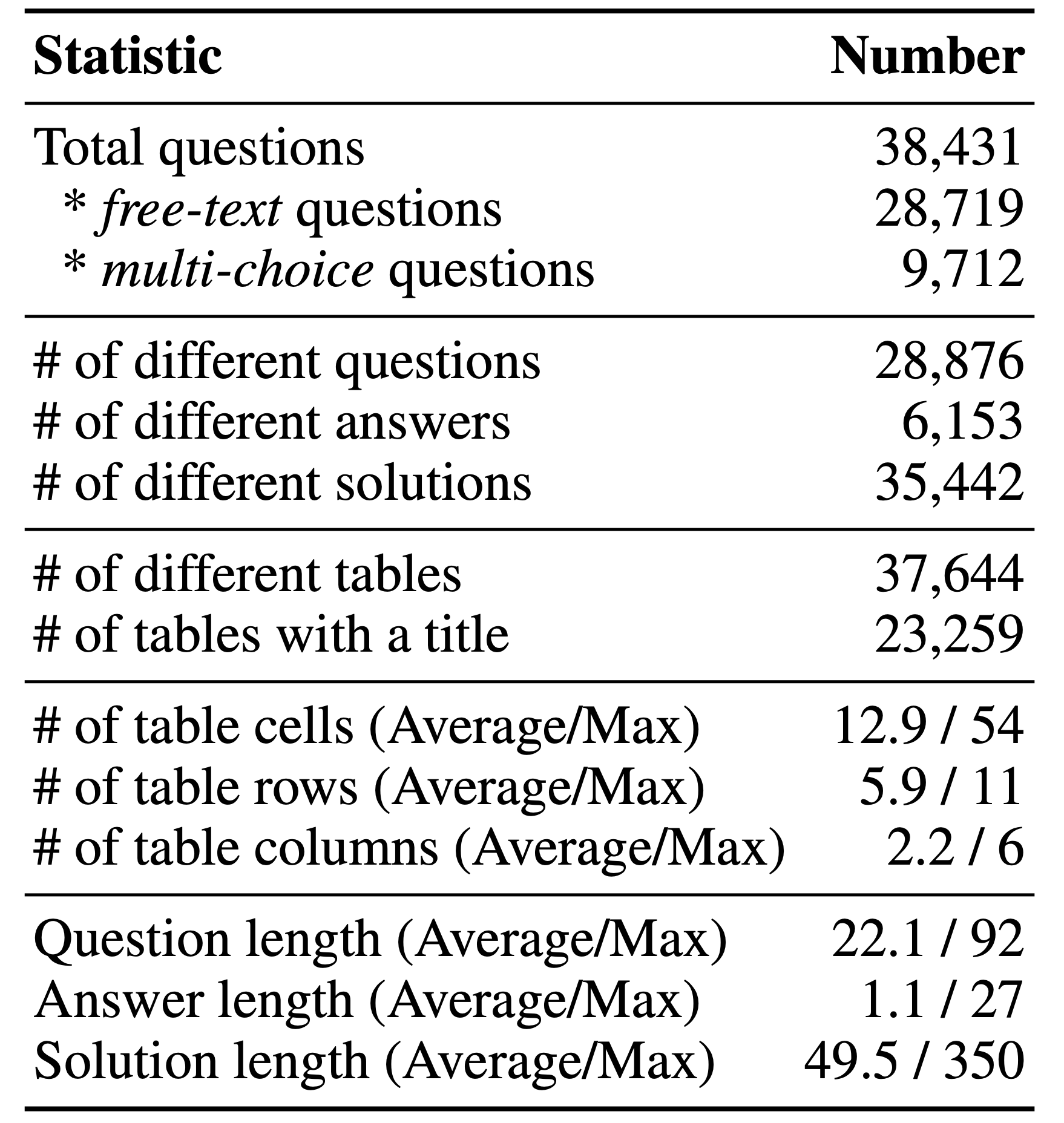
The main statistics for TabMWP are shown in the table below.
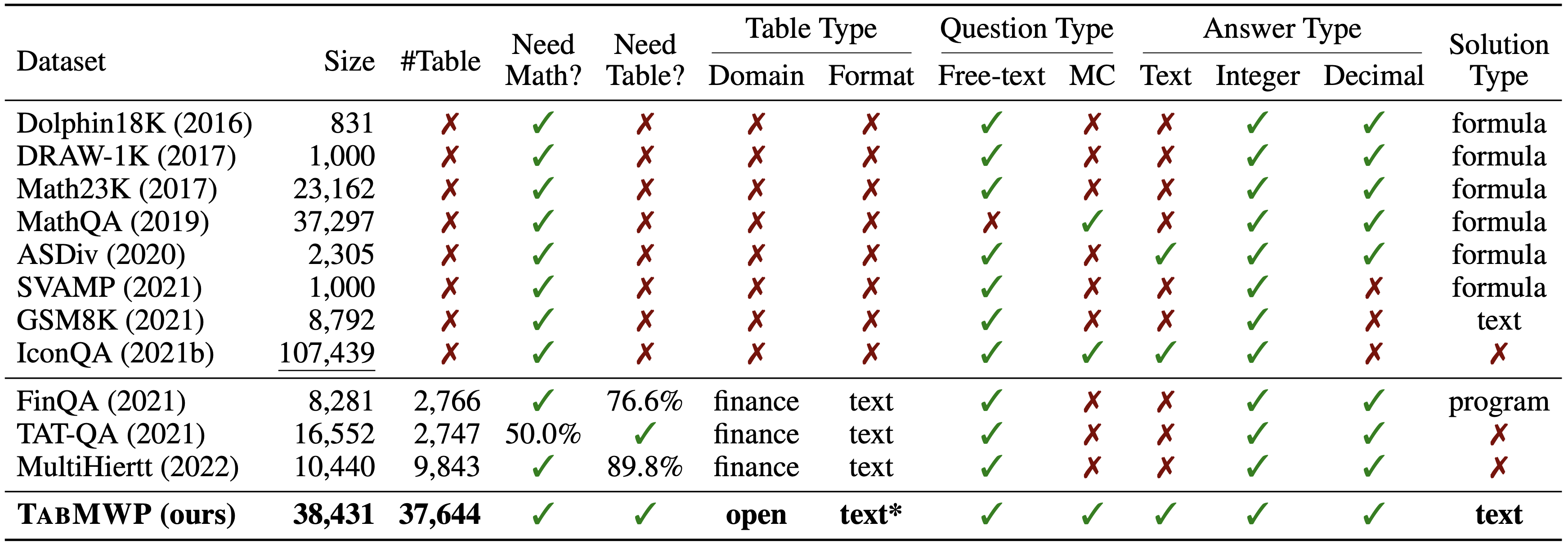
TabMWP differs from related datasets in various aspects. To the best of our knowledge, TabMWP is the first dataset to study math word problems over tabular context on open domains and is the largest in terms of data size.
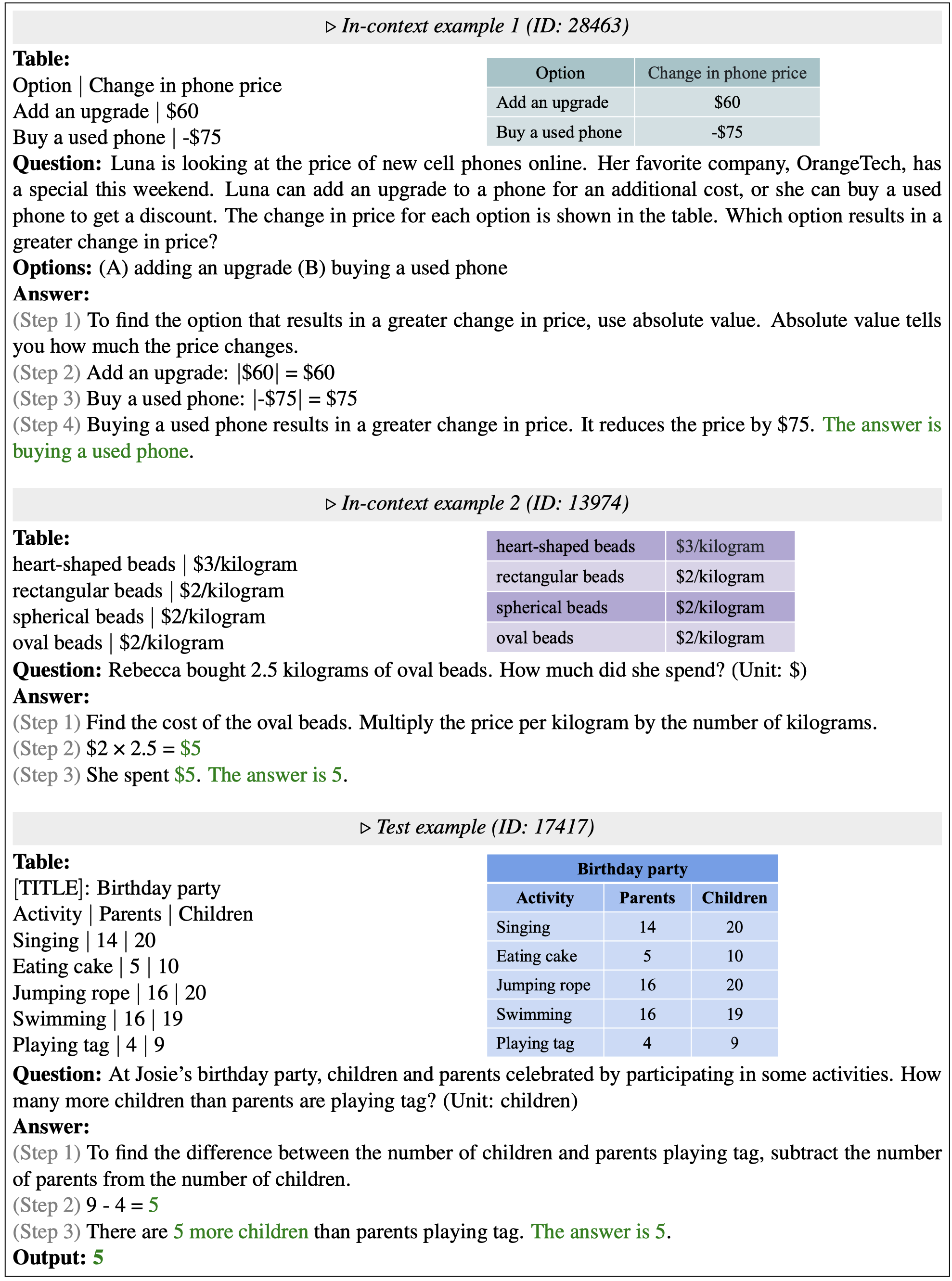
Below shows two in-context examples selected by PromptPG, the prompt, and the correct prediction. The selected examples require similar abilities of mathematical reasoning to the test example.
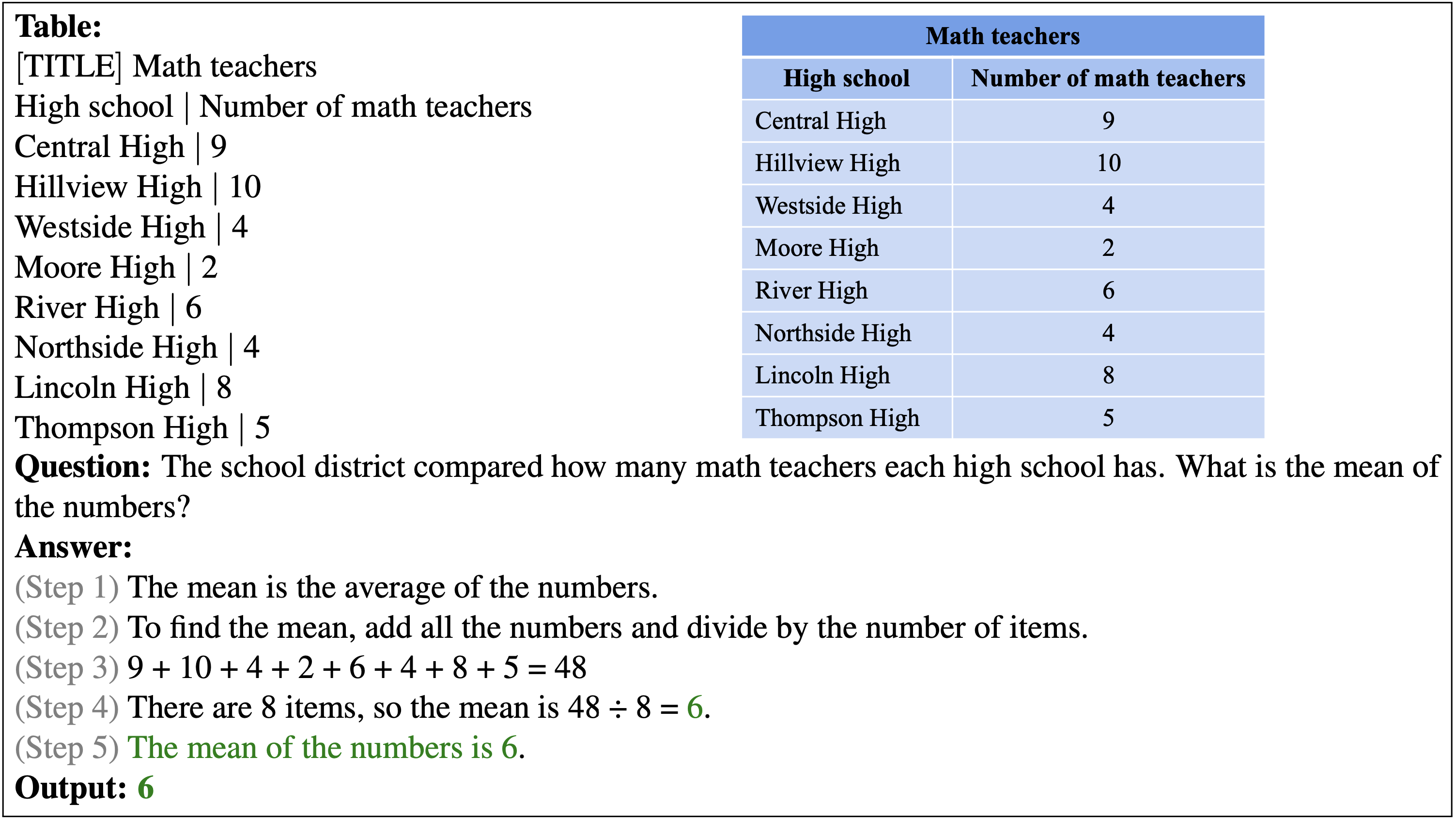
Below shows the correct prediction from our PromptPG for a free-text question example. This example requires taking the mean of eight numbers from the table via addition and division.
Below shows the correct prediction from our PromptPG for a free-text question example. In this example, the model is asked to understand a hierarchical tax report and calculate the pay after taxes

Below shows the correct prediction from our PromptPG for a multi-choice question. There are 9 rows and 6 columns in the given tabular context. Our model successfully locates the target cells in the table and performs multi-hop reasoning to predict the correct answer.

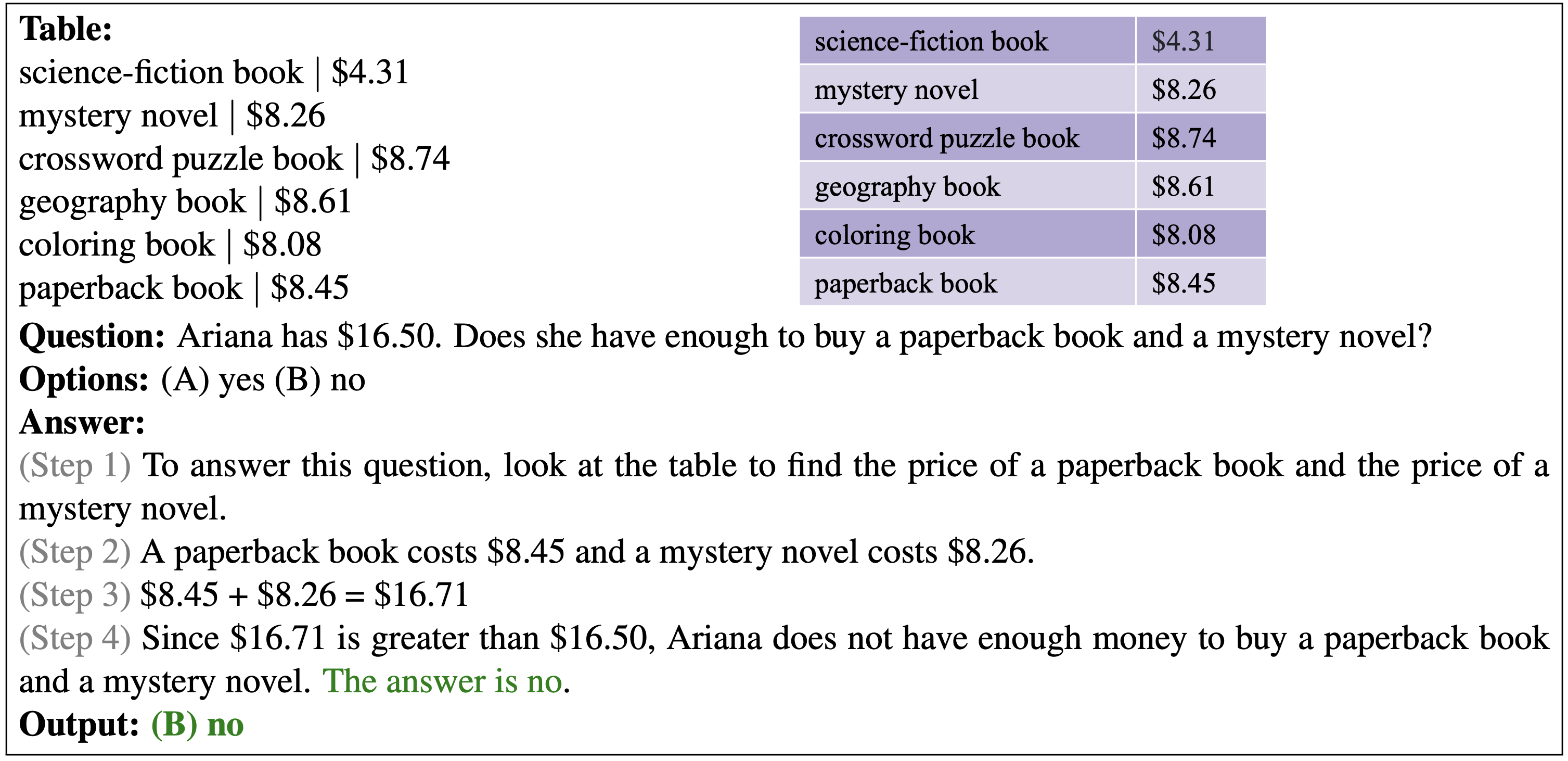
Below shows the correct prediction from our PromptPG for a multi-choice question with Boolean options. It needs to compare the budget and the total costs to verify if Ariana has enough money.
Below shows the wrong prediction from our PromptPG for a free-text question example. Our model retrieves the wrong price for the rose quartz, thus calculating the wrong cost sum of three items.

Below shows the wrong prediction from our PromptPG for a free-text question example. In this example, the problem is provided with an abstract Stem-Leaf table. Our model fails to understand this domain-specific table and lacks a high-level ability of logical reasoning to get the correct answer.

Below shows the wrong prediction from our PromptPG for a free-text question example. It seems that our model has a limited ability to order numbers in the mathematical domain.
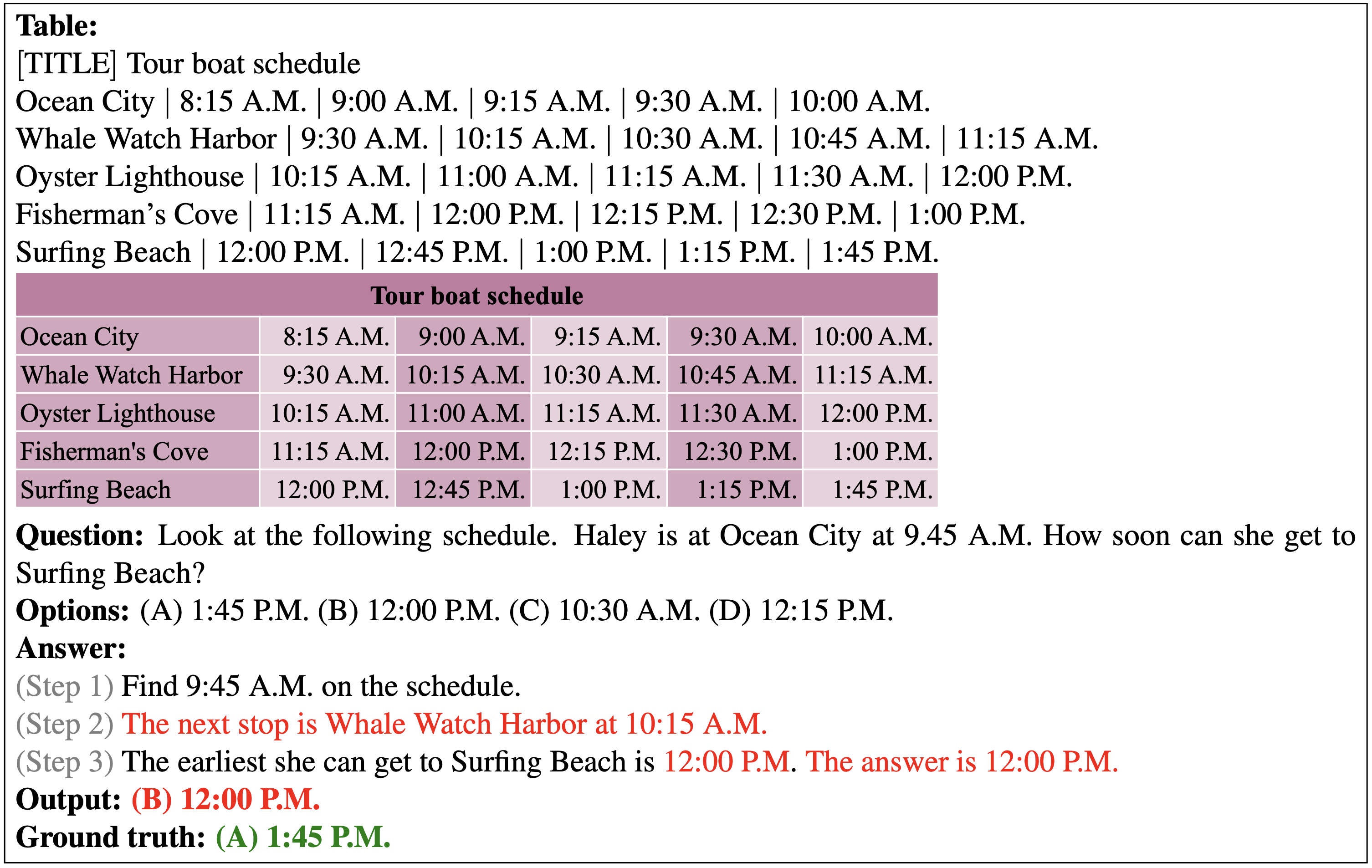
Below shows the wrong prediction from our PromptPG for a multi-choice question example. In this example, the query of the current time provided in the question text does not hit any time slot exactly in the tabular context. Therefore, the model fails to locate the accurate time for the next stop.
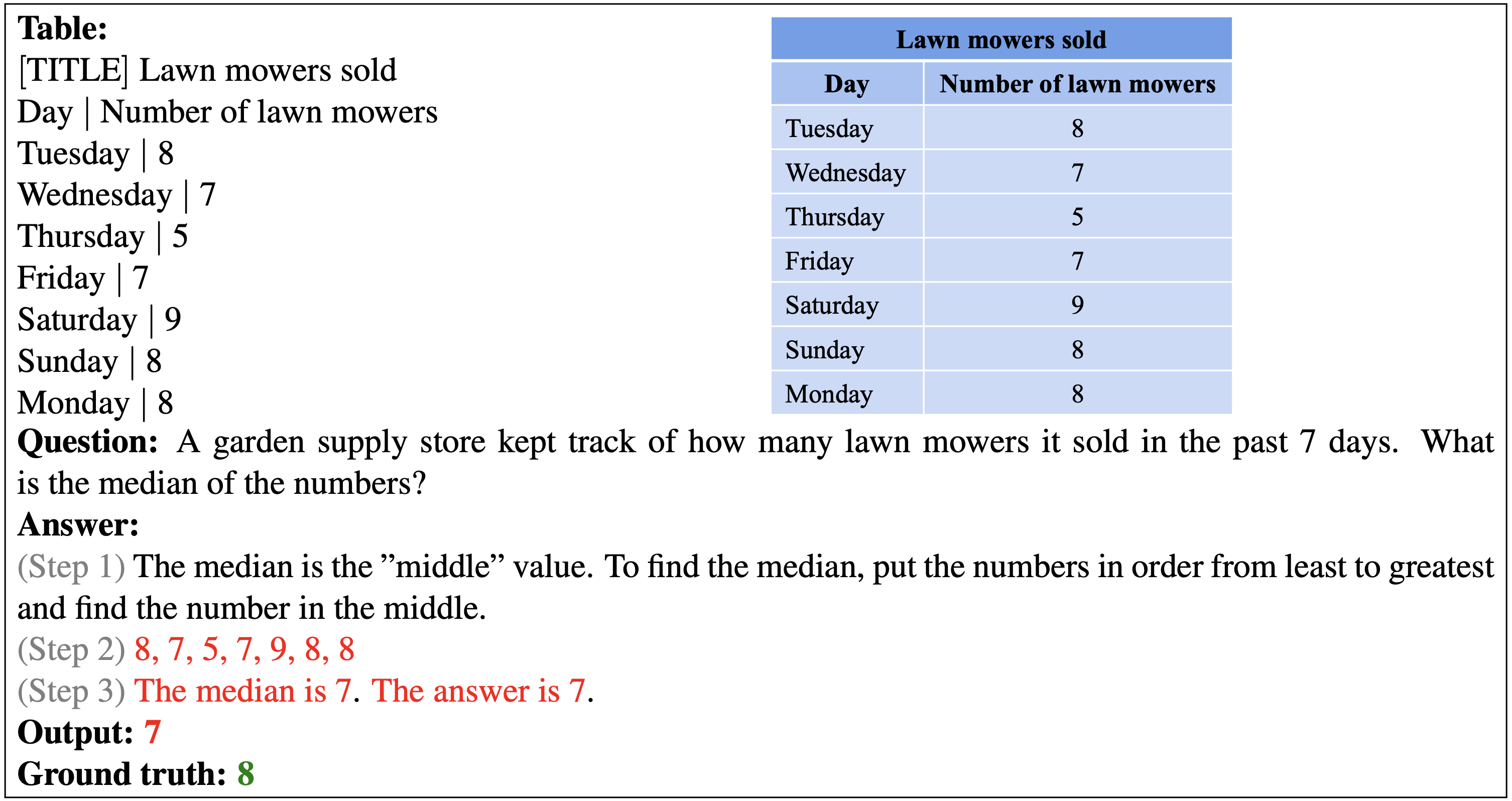
Below shows the wrong prediction from our PromptPG for a free-text question example. The example poses a challenge for the model to perform an arithmetic operation on a long chain of numbers.
